
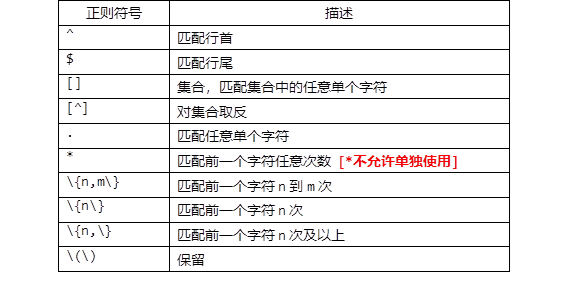
正则表达式 、 sed基本用法 、 sed应用案例

一、正则表达式
可以使用若干符号配合某工具对字符串进行增删改查操作
head -5 /etc/passwd > user //准备素材
grep ^root user //找以root开头的行 grep bash$ user //找以bash结尾的行 grep ^$ user //找空行 grep -v ^$ user //显示除了空行的内容 grep "[root]" user //找r、o、t任意一个字符 grep "[rot]" user //效果同上 grep "[^rot]" user //显示r或o或t以外的内容 grep "[0123456789]" user //找所有数字 grep "[0-9]" user //效果同上 grep "[^0-9]" user //显示数字以外内容 grep "[a-z]" user //找所有小写字母 grep "[A-Z]" user //找所有大写字母 grep "[a-Z]" user //找所有字母 grep "[^0-9a-Z]" user //找所有符号
grep "." user //找任意单个字符,文档中每个字符都可以理解为任意字符
grep "r..t" user //找rt之间有2个任意字符的行
grep "r.t" user //找rt之间有1个任意字符的行,没有匹配内容,就无输出
grep "*" user //错误用法,*号是匹配前一个字符任意次,不能单独使用
grep "ro*t" user //找rt,中间的o有没有都行,有几次都行
grep ".*" user //找任意,包括空行 .与*的组合在正则中相当于通配符的效果
grep "ro\{1,2\}t" user //找rt,中间的o可以有1~2个
grep "ro\{2,6\}t" user //找rt,中间的o可以有2~6个
grep "ro\{1,\}t" user //找rt,中间的o可以有1个以及1个以上
grep "ro\{3\}t" user //找rt,中间的o必须只有有3个-------------------------------------------------------------------
以上命令均可以加-E选项并且去掉所有\,改成扩展正则的用法,比如
grep "ro\{1,\}t" user
可以改成
grep -E "ro{1,}t" user
或者
egrep "ro{1,}t" user
grep "ro\{1,\}t" user //使用基本正则找o出现1次以及1次以上
egrep "ro{1,}t" user //使用扩展正则,效果同上,比较精简
egrep "ro+t" user //使用扩展正则,效果同上,最精简
grep "roo\{0,1\}t" user //使用基本正则找第二个o出现0~1次
egrep "roo{0,1}t" user //使用扩展正则,效果同上,比较精简
egrep "roo?t" user //使用扩展正则,效果同上,最精简
egrep "(0:){2}" user //找连续的2个0: 小括号的作用是将字符组合为一个整体
egrep "root|bin" user //找有root或者bin的行
egrep "the\b" abc.txt //在abc.txt文件中找the,右边不允许出现数字、字母、下划线
egrep "\bthe\b" abc.txt //两边都不允许出现数字、字母、下划线
egrep "\<the\>" abc.txt //效果同上----------------------------------------------------
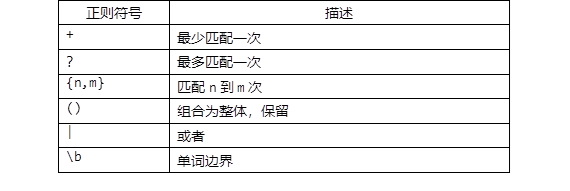
二、sed 流式编辑器
可以对文档进行非交互式增删改查,逐行处理
用法:
| sed 选项 条件 指令
sed 被处理文档
选项 -n 屏蔽默认输出 -r 支持扩展正则 -i 修改源文件
指令 p 输出 d 删除 s 替换
条件 行号 //
-e<script>或--expression=<script>:以选项中的指定的script来处理输入的文本文件; -f<script文件>或--file=<script文件>:以选项中指定的script文件来处理输入的文本文件; -h或--help:显示帮助; -n或--quiet或——silent:仅显示script处理后的结果; -V或--version:显示版本信息。
sed命令
a\ # 在当前行下面插入文本。 i\ # 在当前行上面插入文本。 c\ # 把选定的行改为新的文本。 d # 删除,删除选择的行。 D # 删除模板块的第一行。 s # 替换指定字符 h # 拷贝模板块的内容到内存中的缓冲区。 H # 追加模板块的内容到内存中的缓冲区。 g # 获得内存缓冲区的内容,并替代当前模板块中的文本。 G # 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 l # 列表不能打印字符的清单。 n # 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。 N # 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。 p # 打印模板块的行。 P # (大写) 打印模板块的第一行。 q # 退出Sed。 b lable # 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。 r file # 从file中读行。 t label # if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 T label # 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。 w file # 写并追加模板块到file末尾。 W file # 写并追加模板块的第一行到file末尾。 ! # 表示后面的命令对所有没有被选定的行发生作用。 = # 打印当前行号码。 # # 把注释扩展到下一个换行符以前。
sed替换标记
g # 表示行内全面替换。 p # 表示打印行。 w # 表示把行写入一个文件。 x # 表示互换模板块中的文本和缓冲区中的文本。 y # 表示把一个字符翻译为另外的字符(但是不用于正则表达式) \1 # 子串匹配标记 & # 已匹配字符串标记
sed元字符集
^ # 匹配行开始,如:/^sed/匹配所有以sed开头的行。
$ # 匹配行结束,如:/sed$/匹配所有以sed结尾的行。
. # 匹配一个非换行符的任意字符,如:/s.d/匹配s后接一个任意字符,最后是d。
* # 匹配0个或多个字符,如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] # 匹配一个指定范围内的字符,如/[sS]ed/匹配sed和Sed。
[^] # 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
\(..\) # 匹配子串,保存匹配的字符,如s/\(love\)able/\1rs,loveable被替换成lovers。
& # 保存搜索字符用来替换其他字符,如s/love/ **&** /,love这成 **love** 。
\< # 匹配单词的开始,如:/\<love/匹配包含以love开头的单词的行。
\> # 匹配单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\} # 重复字符x,m次,如:/0\{5\}/匹配包含5个0的行。
x\{m,\} # 重复字符x,至少m次,如:/0\{5,\}/匹配至少有5个0的行。
x\{m,n\} # 重复字符x,至少m次,不多于n次,如:/0\{5,10\}/匹配5~10个0的行。sed用法实例
替换操作:s命令
替换文本中的字符串:
sed 's/book/books/' file
-n选项 和 p命令 一起使用表示只打印那些发生替换的行:
sed -n 's/test/TEST/p' file
直接编辑文件 选项-i ,会匹配file文件中每一行的所有book替换为books:
sed -i 's/book/books/g' file
全面替换标记g
使用后缀 /g 标记会替换每一行中的所有匹配:
sed 's/book/books/g' file
当需要从第N处匹配开始替换时,可以使用 /Ng:
echo sksksksksksk | sed 's/sk/SK/2g'skSKSKSKSKSK echo sksksksksksk | sed 's/sk/SK/3g'skskSKSKSKSK echo sksksksksksk | sed 's/sk/SK/4g'skskskSKSKSK
定界符
以上命令中字符 / 在sed中作为定界符使用,也可以使用任意的定界符:
sed 's:test:TEXT:g'sed 's|test|TEXT|g'
定界符出现在样式内部时,需要进行转义:
sed 's/\/bin/\/usr\/local\/bin/g'
删除操作:d命令
删除空白行:
sed '/^$/d' file
删除文件的第2行:
sed '2d' file
删除文件的第2行到末尾所有行:
sed '2,$d' file
删除文件最后一行:
sed '$d' file
删除文件中所有开头是test的行:
sed '/^test/'d file
sed -n 'p' user //输出所有行 sed -n '1p' user //输出第1行 sed -n '2p' user //输出第2行 sed -n '3p' user //输出第3行 sed -n '2,4p' user //输出2~4行 sed -n '2p;4p' user //输出第2行与第4行 sed -n '3,+1p' user //输出第3行以及后面1行 sed -n '/^root/p' user //输出以root开头的行 sed -n '/root/p' user //输出包含root的行 sed -nr '/^root|^bin/p' user //输出以root开头的行或bin开头的行,|是扩展正则,需要r选项 sed -n '1!p' user //输出除了第1行的内容,!是取反 sed -n '$p' user //输出最后一行 sed -n '=' user //输出行号,如果是$=就是最后一行的行号
以上操作,如果去掉-n,在将p指令改成d指令就是删除
输出所有行 sed -n 'p' abc.txt
输出第4行 sed -n '4p' abc.txt
输出第4~7行 sed -n '4,7p' abc.txt
输出以bin开头的行 sed -n '/^bin/p' abc.txt
输出文件的总行数 sed -n '$=' abc.txt
删除第3~5行 sed '3,5d' abc.txt
删除所有包含xml的行 sed '/xml/d' abc.txt
删除不包含xml的行 sed '/xml/!d' abc.txt
删除以install开头的行 sed '/^install/d' abc.txt
删除文件的最后一行 sed '$d' abc.txt
删除所有空行 sed '/^$/d' abc.txt
替换
sed 's/2017/6666/' shu.txt //把所有行的第1个2017替换成6666 sed 's/2017/6666/2' shu.txt //把所有行的第2个2017替换成6666 sed '1s/2017/6666/' shu.txt //把第1行的第1个2017替换成6666 sed '3s/2017/6666/3' shu.txt //把第3行的第3个2017替换成6666 sed 's/2017/6666/g' shu.txt //所有行的所有个2017都替换 sed '/2024/s/2017/6666/g' shu.txt //找含有2024的行,将里面的所有2017替换成6666
如果想把 /bin/bash 替换成 /sbin/sh 怎么操作?
sed -i '1s/bin/sbin/' user //传统方法可以一个一个换,先换一个 sed -i '1s/bash/sh/' user //再换一个
如果想一起一步替换:
sed 's//bin/bash//sbin/sh/' user //直接替换,报错
sed 's/\/bin\/bash/\/sbin\/sh/' user //使用转义符号可以成功,但不方便
sed 's!/bin/bash!/sbin/sh!' user //最佳方案,更改s的替换符
sed 's(/bin/bash(/sbin/sh(' user //替换符号可以用所有数字键上的-------------------------------------------------------------------
httpd2号端口开启服务
#!/bin/bash setenforce 0 //关闭selinux yum -y install httpd &> /dev/null //安装网站 echo "sed-test~~~" > /var/www/html/index.html //定义默认页 sed -i '/^Listen 80/s/0/2/' /etc/httpd/conf/httpd.conf //修改配置文件,将监听端口修改为82 systemctl restart httpd //开服务 systemctl enable httpd //设置开机自启然后运行脚本 curl 192.168.2.5:82 //脚本运行之后,测试82端口看到页面即可 sed-test~~~ netstat -ntulp | grep httpd //检查服务的端口是否为82
-------------------------------------------------------------------
bash
“账户名 --> 密码” 的格式存储在一个文件中
#!/bin/bash
u=$(sed -n '/bash$/s/:.*//p' /etc/passwd) //找到passwd文档中以bash结尾的行,然后将行中冒号以及冒号后面内容都删除此处的p代表仅仅显示s替换成功的行,最后赋值给u
for i in $u //将那些用bash的账户名交给for循环
do
n=$(grep $i: /etc/shadow) //用每个账户名去shadow中找对应信息
n=${n#*:} //掐头,从左往右删除到第1个冒号
n=${n%%:*} //去尾,从右往左删除到最后一个冒号
经过上述步骤,n就是最终要的密码了
echo "$i --> $n" //按格式喊出,如果要存到文件中就用追加重定向
done正则表达式补充
\w匹配数字、字母、下划线 egrep "roo\w" user //找roo后面是数字、字母、下划线的字符串 \s 匹配空格、tab键 egrep "roo\s" user //找roo后面是1个空格或者tab键打出来的空格的字符串,如果没有 就不输出
sed其他指令补充
a行下追加 i行上添加 c替换整行
sed 'a 666' user //所有行的下面追加666 sed '1a 666' user //第1行的下面追加666 sed '/^bin/a 666' user //在以bin开头的行的下面追加666 sed 'i 666' user //所有行的上面添加666 sed '5i 666' user //第5行的上面添加666 sed '$i 666' user //最后1行的上面添加666 sed 'c 666' user //所有行都替换成666 sed '1c 666' user //替换第1行为666
-----------------------------------------------------------
练习:
1 简述grep工具的-q选项的含义(egrep同样适用)。
2 正则表达式中的+、?、*分别表示什么含义?
3 如何编写正则表达式匹配11位的手机号?
4 简述sed条件的作用及表示方式。
参考答案:
1 简述grep工具的-q选项的含义(egrep同样适用)。
选项-q的作用是静默、无任何输出,效果类似于正常的grep操作添加了&> /dev/null来屏蔽输出
2 正则表达式中的+、?、*分别表示什么含义?
这三个字符用来限制前面的关键词的匹配次数,含义分别如下:
+:最少匹配一次,比如a+可匹配a、aa、aaa等
?:最多匹配一次,比如a?可匹配零个或一个a
*:匹配任意多次,比如a*可匹配零个或任意多个连续的a
3 如何编写正则表达式匹配11位的手机号?
准备测试文件:
[root@svr5 ~]# cat tel.txt
01012315
137012345678
13401234567
10086
18966677788
提取包含11位手机号的行:
[root@svr5 ~]# egrep '^1[0-9]{10}$' tel.txt //这里^代表以数字1开头,后面有10个数字作为结尾
13401234567
18966677788
4 简述sed条件的作用及表示方式。
作用:条件控制sed需要处理文本的范围,不加则逐行处理所有行
表示方式:条件可以使用行号或正则表达式
over



